Importance sampling
Continuing with our rejection sampling example, we now turn to importance sampling. We still have a target distribution f(x) and a proposal distribution q(x). But instead of throwing away samples like we did in rejection sampling, we keep all the samples but give them weights. The weights are proportional to the ratio of the target to the proposal. They are only proportional because we renormalize them to sum to 1.
Set up the target and proposal densities and sample.
a = 5
b = 12
target = function(x) dbeta(x,a,b)
proposal = dunif
n = 1000
points = runif(n)So far, everything is the same as rejection sampling. Now we calculate the weights.
w = target(points)/proposal(points)
curve(target,lwd=2)
points(points,w, col="red", pch=1, lwd=2)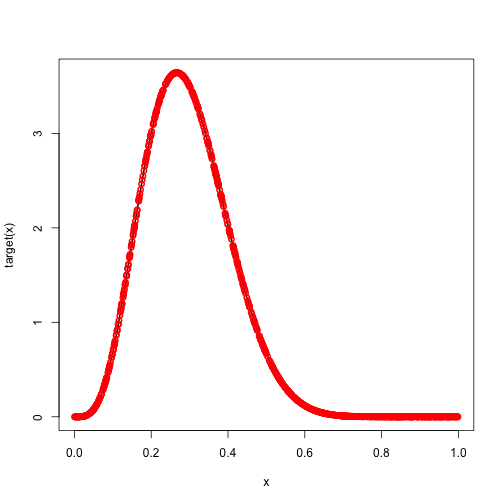
Since our proposal is the uniform distribution, the unnormalized weights exactly match the density of our target. We can use this weighted sample for any purpose, e.g. estimation of expectations or densities. But sometimes it is more convenient to have an unweighted sample. If so, we can resample from our weights with replacement to obtain an unweighted sample.
points2 = points[sample(n, n, w, replace=TRUE)]These unweighted samples should look like our target density.
hist(points2, freq=FALSE)
curve(target, lwd=2, add=TRUE)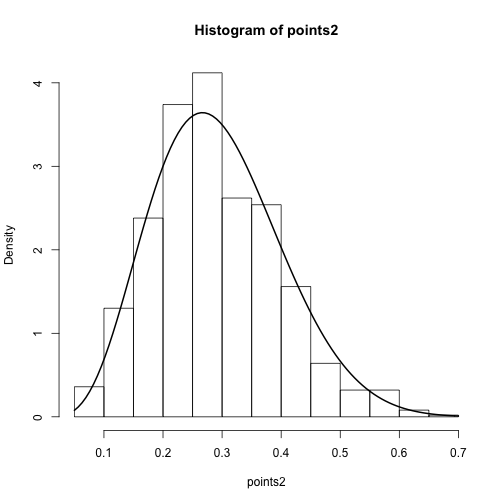
But notice that there are duplications in this sample.
dup = table(as.factor(points2))The plot below shows that the duplicated points are more often found where the target density is high.
plot(as.numeric(names(dup)), as.numeric(dup), xlim=c(0,1), ylim=c(0,10), col="blue", ylab="# of duplicates", xlab="Location", lwd=2)
points(points,rep(0,n), lwd=2, col="red", pch=1)
curve(target, lwd=2, add=TRUE, col="gray")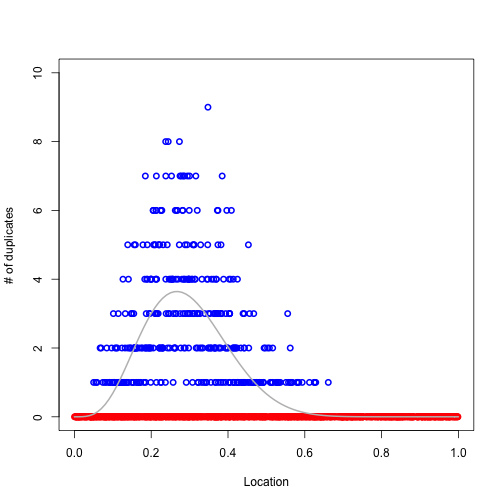
blog comments powered by Disqus